Cơ hội
Nhận hoa hồng
Nhận hoa hồng
Lên
đến
15
%


 Dịch vụBạn đang Kinh doanh dịch vụ
Dịch vụBạn đang Kinh doanh dịch vụ
 Dịch vụ quảng cáo đa kênhĐem doanh nghiệp của bạn đến tận mắt khách hàng
Dịch vụ quảng cáo đa kênhĐem doanh nghiệp của bạn đến tận mắt khách hàng  Remarketing adsTiếp thị lại đa kênh đem về nguồn khách hàng lớn
Remarketing adsTiếp thị lại đa kênh đem về nguồn khách hàng lớn Domain riêngSở hữu ngay tên miền “ĐỘC LẠ”cho doanh nghiệp
Domain riêngSở hữu ngay tên miền “ĐỘC LẠ”cho doanh nghiệp  Email doanh nghiệpTạo dựng sự uy tín, chuyên nghiệp trong mắt khách hàng
Email doanh nghiệpTạo dựng sự uy tín, chuyên nghiệp trong mắt khách hàng  SSLTăng cường bảo mật và uy tín hơn trong mắt khách hàng
SSLTăng cường bảo mật và uy tín hơn trong mắt khách hàng

03 Tháng Tư, 2023
Trần Thanh Quang
Marketing Director
Robot.txt là tập tin văn bản trong thư mục gốc của website. Nó cung cấp chỉ dẫn cho các công cụ tìm kiếm dữ liệu về các site mà họ có thể thu thập thông tin, dữ liệu để lập chỉ mục. Robots.txt là một trong những điều đầu tiên mà mọi người cần phải kiểm tra và tối ưu trong tối ưu kỹ thuật SEO. Bất kì một sự cố hoặc cấu hình sai nào trong File Robots.txt nào của bạn cũng có thể gây ra các vấn đề SEO, tác động tiêu cực đến thứ hạng của web trên bảng tìm kiếm. Vậy File Robots.txt là gì? Hãy cùng Mona Media tìm hiểu trong bài viết này nhé.
File robots.txt là một tập tin đơn giản chuyên được sử dụng trong quản trị website. Nó là một phần của REP (Robots Exclusion Protocol) chứa một nhóm các tiêu chuẩn về web theo quy định. Công dụng của File robots.txt là giúp cho các nhà quản trị web có được sự linh hoạt và chủ động hơn trong việc kiểm soát bọ của Google.

File robots.txt được sử dụng để cấp quyền chỉ mục cho những con bọ của công cụ tìm kiếm. Bất cứ một website nào thì cũng nên sử dụng File robots.txt, đặc biệt là những trang web lớn hoặc đang xây dựng.
Cú pháp của file robots.txt là quy tắc để các trình thu thập dữ liệu, truy cập dữ liệu web – user agents có thể hoặc không thể thu thập dữ liệu các phần của website. Các quy tắc thu thập thông tin này được chỉ định bằng các chỉ thị “disallowing – không cho phép” hoặc “allowing – cho phép” hành vi của một số hoặc tất cả user agents.
Những thuật ngữ bạn thường bắt gặp trong cú pháp của file robots.txt:
Các công cụ của Google và Bing sử dụng 2 biểu thức chính để chỉ các trang hoặc thư mục con mà SEO muốn loại trừ. Hai ký tự được sử dụng là “*” và “$”:
Các cú pháp cơ bản nhất của file robots.txt:
User-agent: [tên user-agent]
Disallow: [chuỗi URL không được phép thu thập thông tin]
Đây là một cú pháp trong file robots.txt hoàn chỉnh. Trên thực tế, một cú pháp có thể chứa nhiều user agents và chỉ thị như disallows – không cho phép, allows – cho phép, crawl-delays – thu thập dữ liệu chậm chễ…). Các chỉ thị được viết liên tục không cách dòng.
Tuy nhiên, trong trường hợp file robots.txt có nhiều lệnh cho 1 bot thì mặc định bot sẽ làm việc với lệnh rõ và đầy đủ nhất. Trong file robots.txt, mỗi bộ user agents sẽ xuất hiện dưới các cú pháp riêng biệt và được phân tách bằng dấu ngắt dòng.
Một số ví dụ khác về các cú pháp lệnh file robots.txt:
User-agent: *
Disallow: /
Khi sử dụng cú pháp này trong tệp robots.txt sẽ yêu cầu tất cả trình thu thập dữ liệu web không thu thập dữ liệu của bất kỳ trang nào trên website, kể cả trang chủ.
User-agent: *
Disallow:
Khi sử dụng cú pháp này, tệp robots.txt sẽ yêu cầu trình thu thập dữ liệu web thu thập dữ liệu tất cả các trang trên website, bao gồm cả trang chủ.
User-agent: Googlebot
Disallow: /thư mục cụ thể/
Cú pháp này yêu cầu user agent thu thập dữ liệu của Google – Googlebot (hoặc user agent khác) không thu thập dữ liệu của bất kỳ trang nào chứa chuỗi url của thư mục.
User-agent: Bingbot
Disallow: /trang web.html.
Cú pháp yêu cầu trình thu thập dữ liệu của Bing – Bingbot không thu thập dữ liệu tại trang cụ thể được nhắc đến.
Ví dụ minh họa về file robots.txt chuẩn
Dưới đây là ví dụ cho tệp robots.txt hạt động cho trang web https://mona.media/:
User-agent: *
Disallow: /wp-admin/
Allow: /
Sitemap: https://mona.media/sitemap_index.xml
Cấu trúc file robots.txt ở trên cho phép toàn bộ các công cụ của Googe truy cập theo link https://mona.media/sitemap_index.xml để tìm đến file robots.txt và phân tích. Đồng thời, công cụ Google cũng index toàn bộ dữ liệu trong các trang trên website https://mona.media/ ngoại trừ trang https://mona.media/wp-admin/.
Việc tạo file robots.txt cho website của mình giúp bạn kiểm soát được việc các bot của công cụ tìm kiếm thu thập thông tin trong các khu vực nhất định tại trang web. Tuy nhiên, khi tại file bạn cần hết sức chú tâm vì nếu sai chỉ thị, các bot của Google có thể không thực hiện index website của bạn.
Rủi ro là vậy nhưng việc tạo file robots.txt cho WordPress cần thiết bởi nhiều lý do như:
Trong quá trình xây dựng web, khi mà tất cả mọi thứ đều chưa được như ý muốn. Đây là khoảng thời gian và nhà tạo lập cần chăn bọ của google để nó không index những nội dung chưa được hoàn thiện. Bạn có thể tìm hiểu thêm về Google Index.
Bạn chỉ nên sử dụng File robots.txt trong quá trình thiết lập hệ thống. Nếu website đang hoạt động một cách ổn định thì đừng chèn các đoạn mã này vào File robots.txt. Bởi làm như vậy, trang web của mọi người sẽ không thể xuất hiện trên bảng kết quả tìm kiếm.
Để xây dựng website hiệu quả bạn có thể tham khảo một số thông tin sau:
Đôi khi việc xây dựng website sẽ gặp khó khăn đối với một số người mới hoặc người không có chuyên môn về lập trình. Lúc đó bạn có thể tham khảo dịch vụ thiết kế website trọn gói của Mona Media.

Sitemap được ví như một tấm bản đồ giúp cho google có thể khám phá về các trang web của bạn. Nếu số lượng bài viết được index của trang web quá lớn mà trang web đó không có Sitemap thì Google sẽ không có đủ tài nguyên để index hết tất cả. Như vậy, một số nội dung quan trọng sẽ không được xuất hiện.
Hiện tại có 3 công cụ giúp quét backlink phổ biến đó là Moz, Majestic và Ahrefs. Các phần mềm này được trang bị chức năng để quét backlink của bất kì một website nào. Lúc này, công dụng của robots.txt sẽ ngăn điều này để khiến cho đối thủ không thể phân tích backlink của mình.
Thông tin chi tiết backlink là gì và các loại link của một website bạn cần biết:
Những mã nguồn của website thường đều có các thư mục cần được bảo mật. Ví dụ như wp-includes, phpinfo.php, wp-admin, memcached, cgi-bin…
Những trang web này chắc chắn không được index. Bởi một khi nội dung được công khai trên internet, các hacker sẽ có thể lấy cắp đi những thông tin quan trọng, thậm chí là tấn công vào hệ thống của bạn. Công dụng của robots.txt sẽ giúp ngăn chặn việc google index các nội dung này.
-> SSL là gì? Vai trò của chứng chỉ bảo mật SSL với Website
Bên cạnh những phần mềm có thể giúp kiểm tra backlink vẫn còn một số phần mềm độc hại khác mà đối thủ có thể sử dụng. Có những con bọ được tạo ra chuyện để sao chép nội dung của người khác. Hoặc những con bọ gửi quá nhiều và nhanh request tới máy chủ của bạn. Điều này khiến cho hệ thống của bạn bị hao phí băng thông và tài nguyên.
Tham khảo:
Những trang thương mại điện tử sẽ có một số tính năng đặc trưng cho người dùng. Chẳng hạn như đăng ký, đăng nhập, đánh giá sản phẩm, giỏ hàng… những chức năng không thể thiếu. Họ thường tạo ra các nội dung trùng lặp, những nội dung này sẽ không để hỗ trợ cho việc SEO từ khóa. Do đó, mọi người có thể sử dụng robots.txt để chặn index các đường dẫn này.
File robots.txt là một file quan trọng được sử dụng để điều khiển việc truy cập của các robot tìm kiếm đến các trang web. Tuy nhiên, cũng có một số hạn chế của file này mà bạn cần phải hiểu rõ để tránh những tác động tiêu cực đến hoạt động của trang web của bạn. Dưới đây là một số hạn chế của file robots.txt:
Trên thực tế, không phải công cụ tìm kiếm nào cũng hỗ trợ các tập lệnh chỉ thị cho phép, không cho phép, thu thập chậm trễ… trong file robots.txt. Do đó, để chủ động bảo mật được dữ liệu doanh nghiệp, người quản trị web nên đặt mật khẩu cho những nội dung riêng tư trên máy chủ.
Thông thường, các trình thu thập dữ liệu web uy tín sẽ thực hiện theo chỉ thị được xây dựng trong file robots.txt. Tuy nhiên, mỗi trình thu thập dữ liệu sẽ có phương pháp phân tích, giải trình dữ liệu khác nhau.
Những trường hợp không thể tránh khỏi là trình thu thập dữ liệu web không thể hiểu được cú pháp lệnh trong file robots.txt. Do đó, các nhà phát triển web cần nắm rõ cú pháp phù hợp để sử dụng cho từng trình thu thập dữ liệu web khác nhau.
Nếu bạn đã chặn một URL trong file robots.txt nhưng URL đó vẫn xuất hiện thì Google vẫn có thể thực hiện thu thập dữ liệu và lập chỉ mục cho URL đó. Trong trường hợp này, bạn nên xóa URL đó trên trang web của mình nếu nội dung trang không quá quan trọng để đảm bảo bảo mật tốt nhất và không ai có thể tìm được URL đó khi thực hiện truy vấn trên Google.

Như đã nói, phần sau User-agent: Dấu * có nghĩa là quy tắc được áp dụng cho tất cả các bots ở khắp nơi trên website. Khi này, file sẽ cho bots biết rằng chúng không được phép vào trong file như mục wp-includes và wp-admin bởi 2 thư mục này chứa rất nhiều thông tin nhạy cảm.
Hãy nhớ rằng đây là một file ảo, do WordPress tự thiết lập khi cài đặt và không thể chỉnh sửa được. Thông thường, vị trí của file robots.txt WordPress sẽ được đặt trong thư mục gốc, thường được gọi là www và public_html. Và để có thể tạo ra file robots.txt cho riêng mình thì mọi người cần phải tạo file mới thay thế cho file cũ trong thư mục gốc.
Mỗi công cụ tìm kiếm hiện nay thực hiện 2 công việc chính là:
Để tiến hành thu thập thông tin website, các công cụ tìm kiếm sẽ đi theo liên kết để chuyển từ trang này đến trang khác. Công cụ thực hiện thu thập dữ liệu thông qua hàng tỷ website và liên kết khác nhau. Hành vi thu thập dữ liệu này còn được gọi là “spidering”.
Khi đến một website, trước khi thực hiện thu thập dữ liệu trong trang, trình thu thập dữ liệu website sẽ tìm kiếm các tệp robots.txt. Nếu tìm thấy một tệp, các bot này thực hiện đọc tệp đó trước khi tiếp tục làm việc trên các trang.
Trong tệp robots.txt chứa thông tin về cách các bot thực hiện thu thập thông tin và có chỉ dẫn về cách thực hiện quá trình này. Nếu tệp robots.txt không chứa bất kỳ chỉ thị nào dành cho các bot hoặc website không tại file, các bot sẽ đi đến mọi trang trong website và làm công việc của mình.
Làm thế nào để bạn kiểm tra được website của mình có tệp robots.txt hay không? Để trả lời được câu hỏi này, bạn chỉ cần nhập tên miền gốc của bạn và thêm /robots.txt và cuối của URL.
Ví dụ: Kiểm tra xem file robots.txt của Mona Media có hay không thì bạn chỉ cần tìm theo cú pháp: mona.media/robots.txt. Nếu sau khi dán vào công cụ tìm kiếm và không có trang .txt nào xuất hiện nghĩa là website không có file robots.txt.

Việc tạo và quản lý file robots.txt là một phần quan trọng trong việc tối ưu hóa SEO cho trang web WordPress của bạn. Dưới đây là hướng dẫn tạo file robots.txt với 3 cách đơn giản trên nền tảng WordPress:
Bạn có thể tạo, chỉnh sửa file robots.txt cho Wordpres trực tiếp trên bảng WordPress Dashboard. Để thực hiện việc này, bạn thực hiện các bước sau:
Bước 1: Đăng nhập website của bạn trên WordPress, tại giao diện trang Dashboard, bạn nhìn phía trái màn hình, nhấn vào SEO → Tools → File editor.
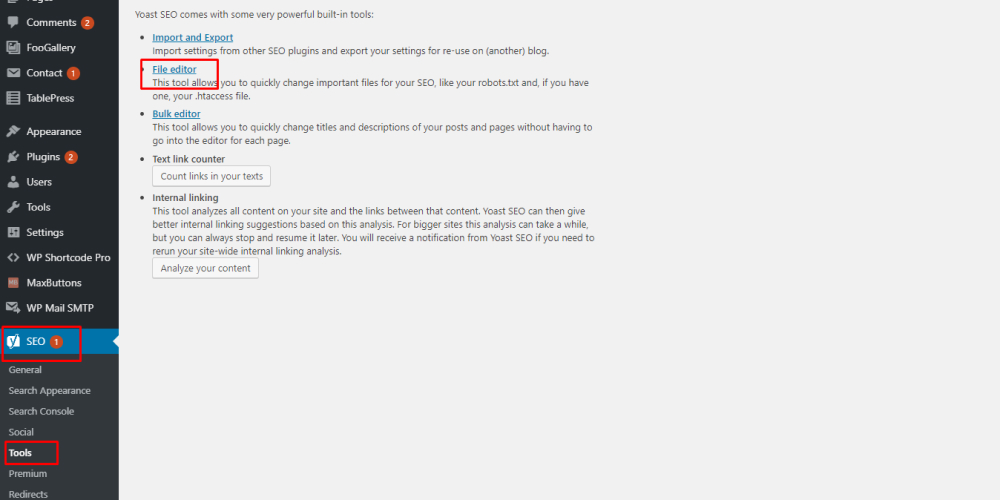
Bước 2: Bạn sẽ thấy mục robots.txt và bạn có thể tạo hoặc chỉnh sửa file robots.txt tại các vị trí này.
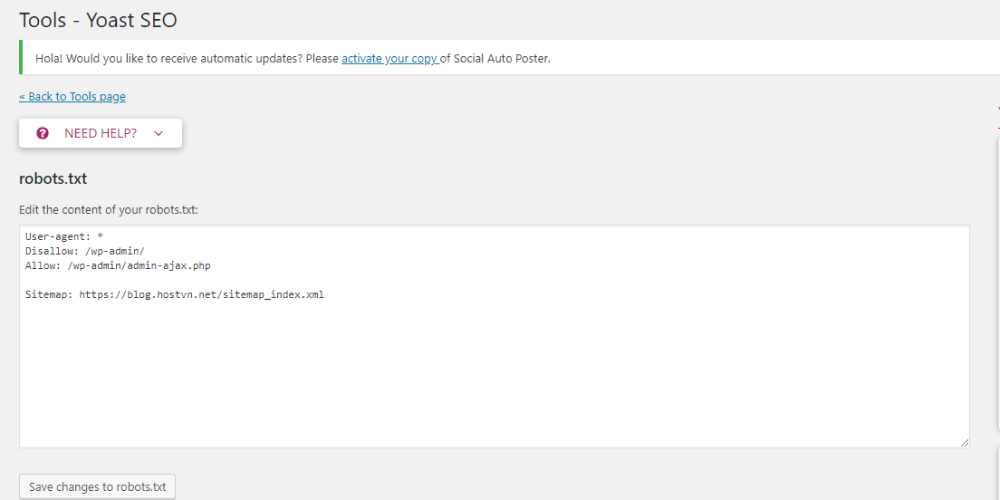
Bạn cũng có thể sử dụng plugin All in One SEO để tạo file robots.txt cho website của mình. Để thực hiện việc này, bạn thực hiện các bước sau:
Bước 1: Truy cập giao diện chính của All in One SEO Pack.
Bước 2: Chọn All in One SEO → Features Manager → click Active cho mục Robots.txt.
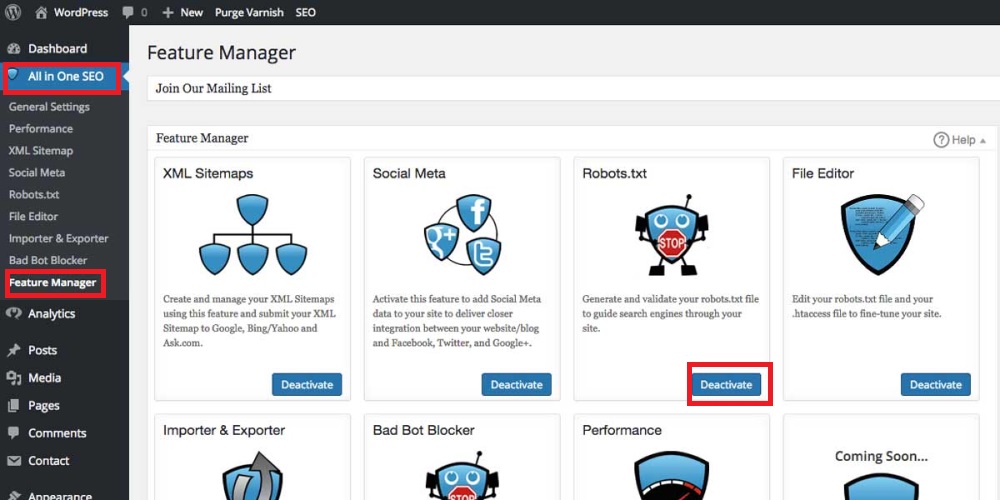
Bước 3: Bạn có thể tạo và chỉnh sửa file robots.txt tại giao diện hiển thị.
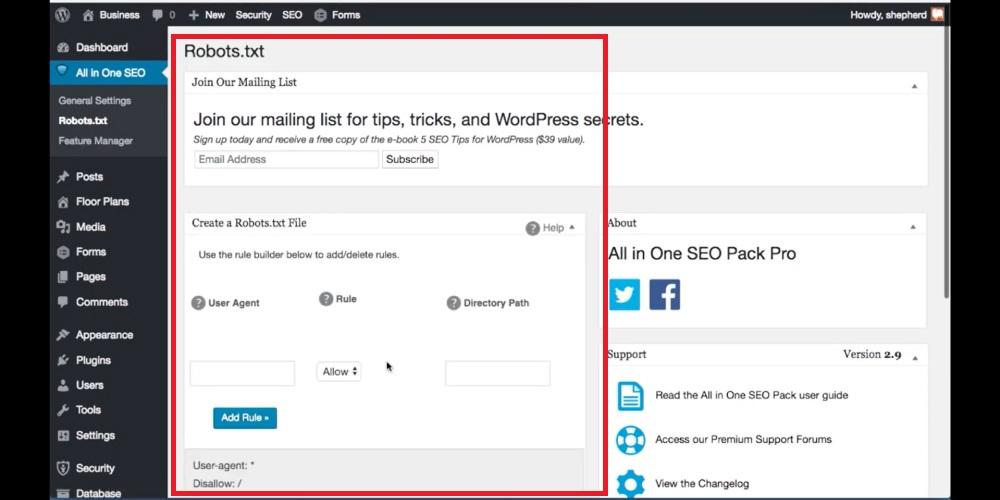
Tham khảo: Top 20+ plugin SEO WordPress tốt nhất năm 2023
Nếu bạn không muốn sử dụng các plugin thì có thể tạo thủ công qua các phần mềm chỉnh sửa. Các phần mềm phổ biến nhất được sử dụng là Notepad và TextEdit. Sau khi hoàn thành tạp file, bạn tải file lên website qua FTP. Chi tiết các bước như sau:
Bước 1: Mở phần mềm chỉnh sửa Notepad hoặc Textedit.
Bước 2: Tạo nội dung file robots.txt
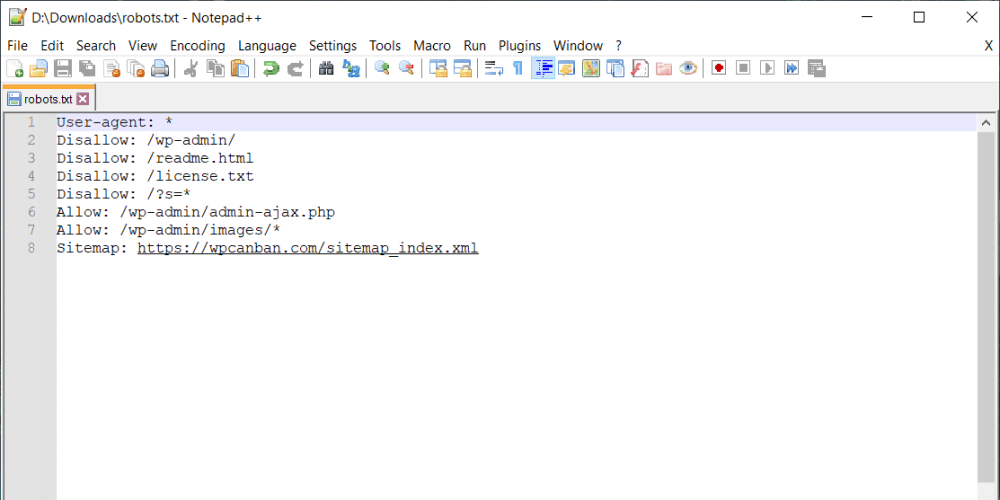
Bước 3: Mở FTP → Chọn public_html → Chọn file robots.txt → Upload để hoàn thành tải lên.
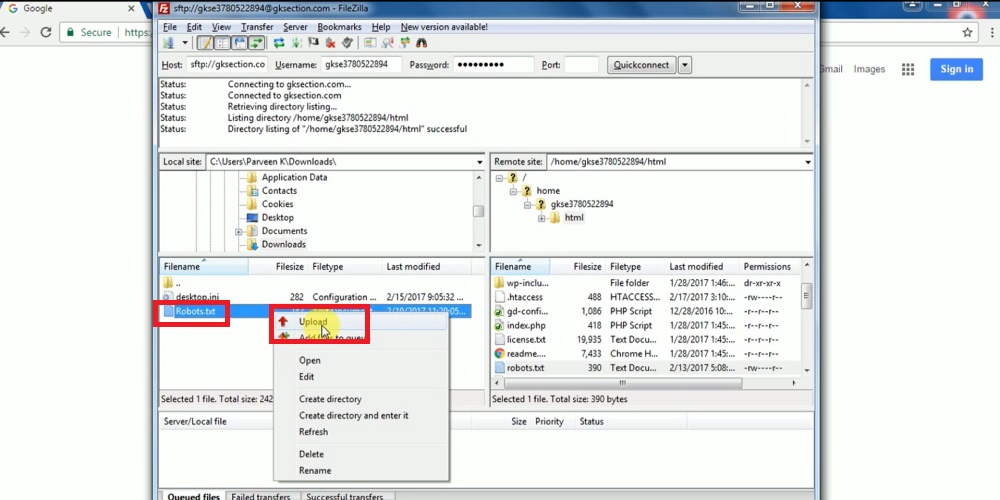
Một số quy tắc về định dạng và vị trí bạn cần lưu ý:
Khi sử dụng file robot.txt, bạn cần lưu ý một số điểm sau:
Khi sử dụng đúng cách, robots.txt có thể giúp quản lý quá trình thu thập thông tin trên trang web và tạo ra trải nghiệm tốt hơn cho người dùng. Dưới đây là một số tình huống cần sử dụng File robots.txt như:
Quá trình xây dựng và hoàn thiện website có thể sẽ phải mất nhiều ngày, đối với những website phức tạp có thể còn phải mất nhiều thời gian hơn. Trong khoảng thời gian này, khi mà các nội dung đưa lên để chạy thử chưa được chỉnh sửa thì mọi người không nên để công cụ tìm kiếm index. Bởi những trang chưa được hoàn thiện tốt sẽ không tốt cho dịch vụ SEO.
Mona Media là một trong những đơn vị cung cấp dịch vụ SEO uy tín, đã thực hiện 350+ dự án cho rất nhiều công ty dành vị trí TOP 1-3. Vậy bạn còn chờ gì mà không liên hệ ngay với chúng tôi qua hotline 1900 636 648 để tối ưu website chuẩn SEO cho thương hiệu.

Khi sử dụng công cụ Search nhúng vào web thì trang kết quả sẽ có một URL riêng. Tất nhiên, Google vẫn có thể index những trang đó. Điều nguy hiểm nhất là đối thủ có thể tận dụng tính năng này để search những từ khóa có nội dung xấu nhằm gây tổn hại cho danh tiếng website của bạn. Chính vì vậy, hãy chặn hết toàn bộ các trang kết quả, không cho đánh giá nội dung và index.
-> Xem thêm: Hướng dẫn kiểm tra backlink xấu và loại bỏ khỏi website của bạn
Những công cụ như Ahref đều có con bọ riêng để thu thập các thông tin về website. Những thông tin đó gồm Backlink, Organic keywords, Referring domains, top pages,…. Đối thủ có thể sử dụng những công cụ này để phân tích website của bạn. Để ngăn chặn điều này mọi người có thể sử dụng robots.txt.

Dưới đây là một số câu hỏi thường gặp, cũng có thể là những thắc mắc của bạn về robots.txt:
Kích thước tối đa của file robots.txt là bao nhiêu?
Kích thước tối đa của file robots.txt là 500 kilobyte.
Làm thế nào để chỉnh sửa robots.txt WordPress?
Mọi người có thể sử dụng phương pháp thủ công hoặc sử dụng Plugin WordPress SEO như Yoast cho phép bạn chỉnh sửa robots.txt file từ WordPress backend.
Vị trí của file robots.txt WordPress trên website ở đâu?
File robots.txt WordPress trên website tại vị trí: domain.com/robots.txt
Điều gì sẽ xảy ra khi Disallow vào nội dung Noindex trong robots.txt?
Các lệnh trong tệp robots.txt sẽ chỉ được áp dụng cho các đường dẫn tương đối.
Cách chặn các Web Crawler?
Tất cả việc mà mọi người cần làm đó là truy cập vào Settings > Reading rồi chọn vào ô bên cạnh tùy chọn Search Engine Visibility. Khi đã được chọn, hãy thêm “meta name=’robots’ content=’noindex,follow’” vào trang web của bạn. WordPress cũng sẽ thay đổi file robots.txt trong trang web của bạn về thêm những dòng này “User-agent: * Disallow: /”.
Với các thông tin mà chúng tôi vừa cung cấp ở trên, chắc hẳn mọi người đã hiểu rõ hơn về File Robots.txt. Tạo và chỉnh sửa file robot.txt WordPress theo ý muốn của bạn nhằm hỗ trợ những con bot của công cụ tìm kiếm thu thập và index trang web của bạn một cách nhanh chóng hơn.
Tham khảo:
Trần Thanh Quang
Marketing Director




Dịch vụ thiết kế
website chuyên nghiệp
Sở hữu website với giao diện đẹp, độc quyền 100%, bảo hành trọn đời với khả năng
mở rộng tính năng linh hoạt theo sự phát triển doanh nghiệp ngay hôm nay!